
System Complexity and Testing

Ever since humans first laid hands on a keyboard, we discovered that writing software is error-prone; we have a nice and clear idea in our brain, but then the computer just doesn’t behave in the way we wanted it to. Or rather, it does exactlywhat it was told to do, which is not what we wanted it to do.
What gives?
Complexity and sources of errors
There are a few compounding sources of errors:
edge cases need to be enumerated and handled very explicitly; a lot of the time it’s hard to know ahead of time how something may fail.
increasing complexity: code is an ever-growing Jenga stack built by millions of other engineers, and you’re just adding a couple more pieces at the top, which can have unintended consequences.
related to the previous point, nobody in the world knows how any system works, end to end, since the levels of complexity are significantly beyond any puny human brain’s capacity.
code evolves with its use: usually, we learn more about the problem space and need to make a codebase do something it wasn’t necessarily designed ahead of time to do.
So what does this say about making systems more resilient? I’d like to categorise complexity (and hence sources of errors) in two:
“internal” complexity is where the internal rules of a system are complicated and easy to get wrong. For the purpose of this discussion, a “system” can be anything from a single function, up to an API or end-to-end system. Good examples of internal complexity are the typical algorithms and data structures you’d study in school or be interviewed against. For example, subtle bugs in binary search persisted for years in critical standard libraries.
“external” complexity is where interactions between various systems are complicated and can cause bugs. Good examples of external complexity are most uses of APIs. The messier the API, the easier it is to misuse it. And most APIs are actually defined by implied boundaries inside a system, which may be poorly or not really documented. A hypothetical example is a website’s payment system getting confused about whether or not the amount it receives has VAT added and failing to bill the customer for it. I suspect this is what most people reading this are dealing with, day to day.
Kinds of systems and associated complexity
These are blurry boundaries, and in practice, there’s a spectrum between them, which means that different systems can be prone to different kinds of errors. This is a useful way of categorising complexity because it suggests different ways of ensuring system correctness.
Caveats apply here that no two systems are the same, parts of systems will map differently (e.g. a database vs. its query language). That said, this should be a good starting point to reason about complexity. Let’s look more closely, from low internal/high external to high internal/low external, taking a few representative examples:
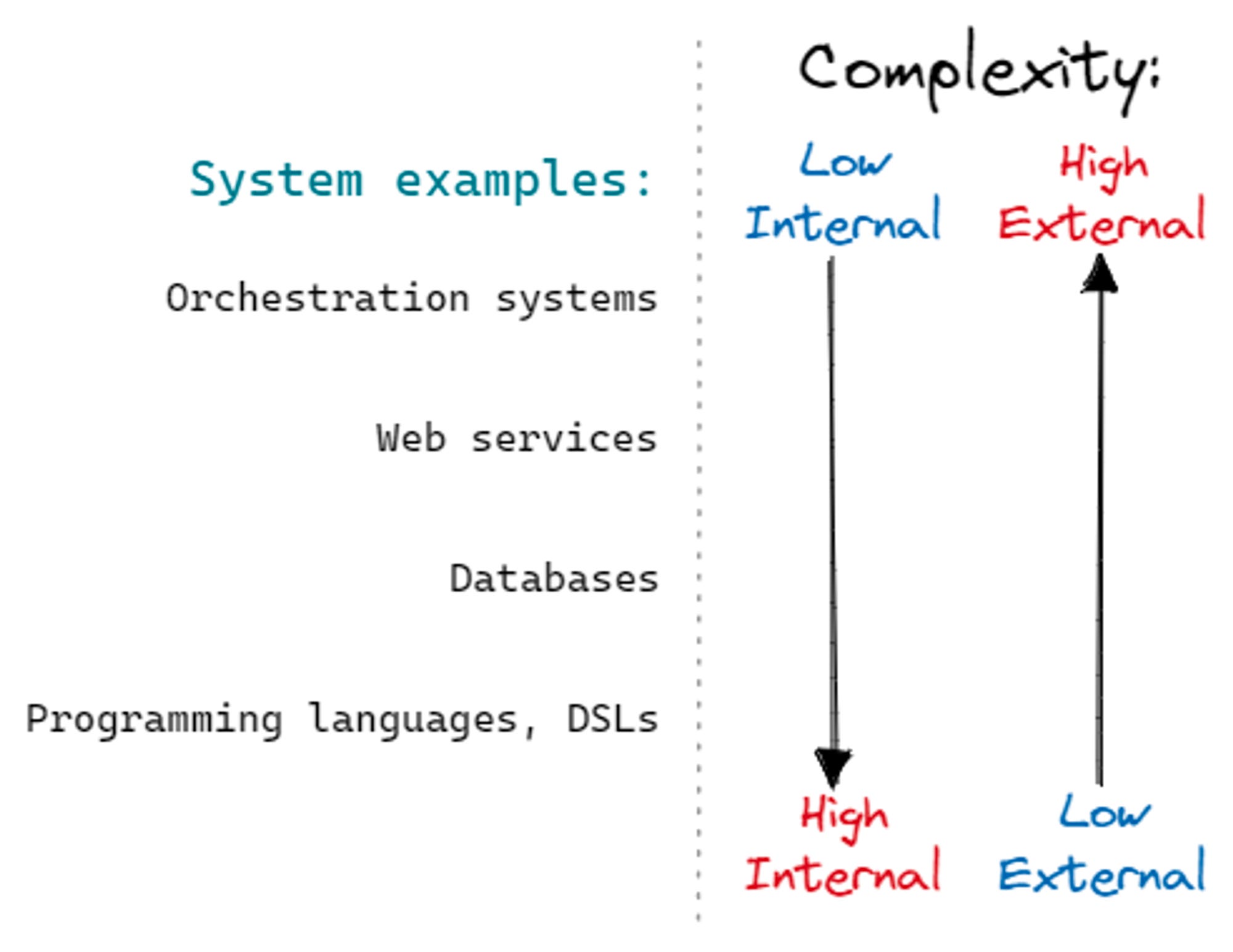
orchestration systems (examples: Kubernetes, Terraform, Apache Airflow):
the systems handle a lot of moving parts, each of which can be finicky and hard to interface with. When they fail, it’s usually due to some implicit assumptions about one of the underlying systems, or maybe not connecting the moving parts correctly.
web services (examples: your typical online shop, blogging platform, etc.):
these also handle a lot of moving parts, but they themselves tend to be the bulk of the business logic, with some of the complexity delegated to lower-level APIs like payment processors. They tend to fail due to internal subsystems making incorrect assumptions about each other, e.g. after refactoring.
databases:
most of the complexity is internal, e.g. strategies for laying data in memory or disk or query interfaces. That said, some of it is external, mostly when dealing with heterogeneous underlying hardware or arcane failure modes. They tend to fail due to internal edge cases and similar.
programming languages and domain-specific languages:
almost all complexity is internal, and failures are almost exclusively due to edge cases in internal logic, e.g. around operator precedence, handling Unicode, implementing a standard library, etc.
Testing strategies
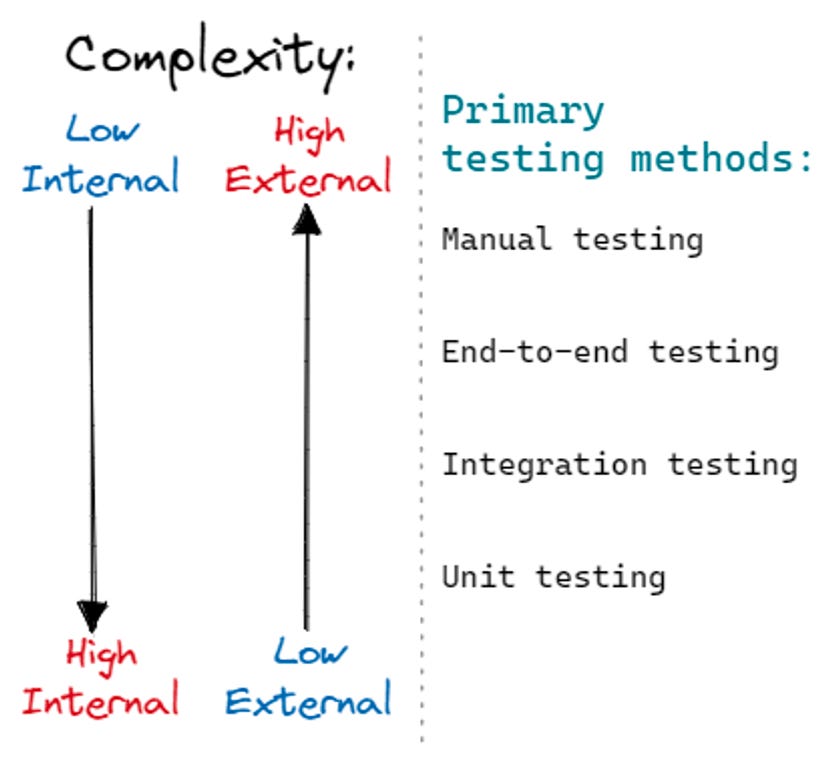
Different testing strategies work better at exposing errors within systems (i.e. internal) vs at the system interface (external). Let’s take a look:
High internal, low external complexity (e.g. programming language):
For these systems, it’s best to use testing strategies that primarily challenge internal logic. Unit testing is the perfect example since it allows you to test each part individually. Unit tests are typically extremely fast which allows us to write a lot of them, including regression unit tests whenever we encounter bugs.
Pros:
These tests tend to be very fast which means you can run a lot of them, and you can easily run them as part of the day-to-day (while developing, as part of CI, etc.).
Can be very useful for catching edge cases that break 0.X% of the use cases.
Cons:
System boundaries are not typically challenged and assumed to be correct. This involves a lot of mocking, and explicitly ignores whole classes of errors.
Refactoring the system can invalidate a lot of unit tests, which slows down the pace of development.
Examples:
The Go test suite has tons of little examples, e.g. expected errors when parsing switch statements.
The SQLite test suite is a marvel that covers both internal (e.g. testcase macros) and external complexity (e.g. Valgrind analysis which simulates an x64 environment end to end).
Low internal, high external complexity (e.g. orchestration engine):
Manual testing is typically useful here, and for some regressions the only option, unfortunately. Ideally, the go-to is integration/end-to-end testing. This typically covers a lot of ground and ensures that subsystems are hooked together properly.
Pros:
These tend to ensure that the system actually behaves as expected, as opposed to unit tests which can sometimes give you a false sense of safety — parts can function perfectly and still lead to a broken system.
This can be very useful for protecting against full system breakages, e.g. as part of the CI/CD pipeline.
Cons:
Tend to be very slow; sometimes they can take hours to execute. This means that not all of them can be run in CI/CD, and instead are sometimes executed on a regular cadence or ad-hoc.
They also tend to be very flakey due to spurious issues; sometimes it’s needed to retry a test a few times to see whether the test or the underlying system is broken.
They tend to cover the “happy path” and are typically not good at exposing edge cases.
Examples:
Searching for “Kubernetes test suite” shows that the lion’s share is end-to-end testing, which is the critical bit for such a system.
The Apache Airflow test suite has some unit tests, but also e.g. Kubernetes tests which run binaries, do HTTP requests, etc.
Conclusion
What does it mean for ensuring that your system is correct?
Make sure you understand the system you’re building: when it fails, why does it do so? Are you primarily concerned with external, or internal complexity?
Cover the most salient failure modes first: if you’re building an orchestration engine, prioritise end to end tests before unit tests (but ideally do both!).
All systems fail; take a look at the past list of bugs and incidents. Which ones are the worst? Is your test suite well positioned to ensure those failures don’t happen again? For example, writing more unit tests for your database is not advised if its current weak point is dealing with hardware failures.
Similarly, take a look at what must absolutely not fail. These would be concerns about human or environmental safety, upholding legal or moral obligations like privacy guarantees, failures which could bring the whole business down, and similar.
TDD and unit tests are not silver bullets — this highly depends on the system you’re building.
Actually, no single testing strategy is going to cover all failure modes; assuming your system is not mission-critical (and most systems are not!), prioritise the strategy which is going to map best to the kinds of failures in your system.
Something else to keep in mind is that testing is not the start and end of system safety. Testing is only one of the tools that you have at your disposal, along with design docs, type checking, code review, feature flags, gradual rollouts, observability/logging, system health dashboards, user reports, incident management, etc. These go beyond the scope of this note but are equally important.